
AI Dubbing 更像一位懂剪辑的“配音搭档”,而不是冷冰冰的TTS引擎。它把“翻译+配音”串成一条顺畅的工作流,尤其适合把中文内容快速做成多语种版本,同时保持原说话人的音色与情绪质感。
功能体验
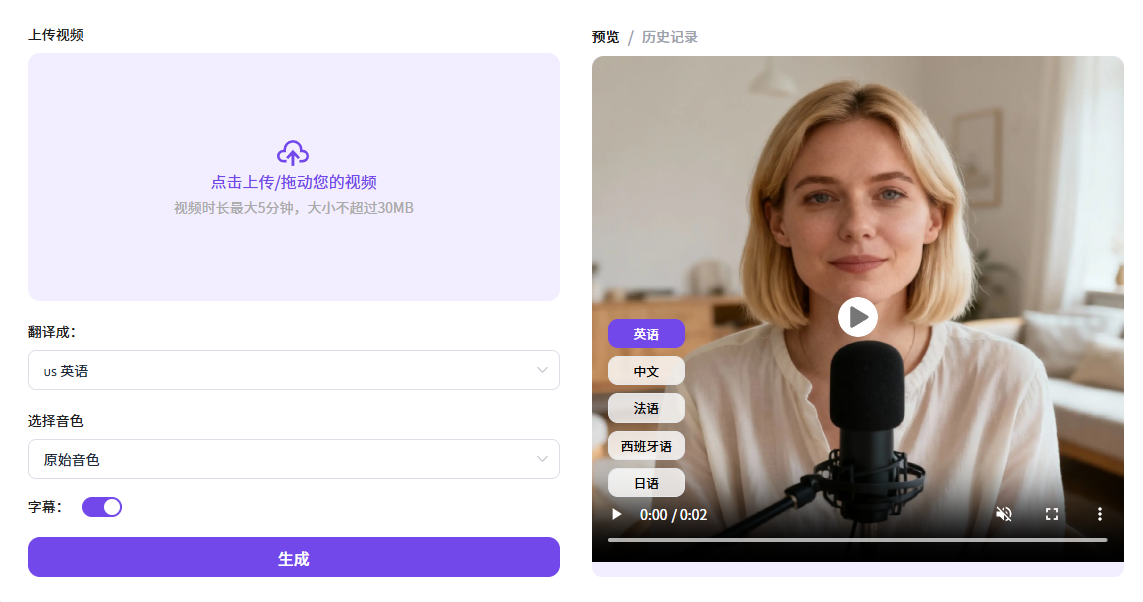
- 上手简单到没门槛:创建项目→选源/目标语言→上传文件或粘贴YouTube/TikTok/X/Vimeo链接→一键生成。处理时能看到进度条,完成后直接在编辑器里预览、改稿、再生,节奏很顺手。
- 多说话人识别与脚本编辑:会自动检测并标注多位发言人,生成可编辑的台词本,方便你逐句微调翻译与时长,直到口音和语气都贴合原片气质。
- 保留音色与情绪:不只是换语言,它会尽量保留原视频里的音色特征、语言模式与情感语调,跨语种听起来更像“同一个人”在说话,而不是千篇一律的播音腔。
效果与限制
- 自然度与一致性:在日常口播、教程、访谈类内容上,情绪和停连拿捏得比较自然;多人对话场景也能分清角色,但极端情绪或复杂修辞下,仍可能出现轻微“合成感”。
- 唇形同步:当前主打“配音+翻译”的声线迁移,并不包含自动口型同步能力;如果你的项目对嘴型要求高,需要另配唇形工具或接受无唇形版本。
操作建议
- 文案口语化:长难句拆短,每句控制信息密度,给AI留出呼吸与停连的空间。
- 先粗后细:先跑通“自动翻译+配音”,再进编辑器逐句微调时间轴与重音,最后整体A/B听感确认。
- 统一风格:固定一位主音色作为频道“声纹”,系列视频保持一致,有助于建立品牌识别。
- 合规与授权:涉及声音克隆/商用时,务必确认素材与授权范围,避免侵权与伦理风险。
评论列表 (0条):
加载更多评论 Loading...